ElastiCache
ElastiCache позволяет легко развернуть кеш для вашего приложения. Доступны 2 самых популярных варианта: Memcache и Redis. С первым я знаком мало, так что буду рассматривать построение кеша на основе Redis. У многих возникает также желание заиспользовать его в качестве брокера сообщений — не стоит, для этого у AWS есть отдельная служба SQS. В данном случае специфика Redis такова, что ноды иногда могут умирать. Как и всё железо у AWS — что-то да обязательно ломается хотя бы раз в год. Хорошая новость состоит в том, что эта ситуация может быть автоматически обработана, и вы ничего не заметите при правильной настройке.
Создание ElastiCache
Как я уже говорил, доступны два вида кеша: Redis и Memcached. В случае второго всё очень просто — мастер + read-реплики, бэкапов нет, восстановление данных тоже нет. Упомяну лишь, что в кластере Memcached каждая нода может выступать в качестве мастера, так что AWS предоставляет утилиту endpoints auto-discovery в разделе ElastiCache Cluster Client. К сожалению, она реализована только на C#, Java и PHP. Интереснее выглядит Redis. У него есть возможность включить режим кластера, в котором реализуется разбиение по шардам.
Redis в режиме кластера
Если ваши данные уже не помещаются в m4.xlarge, то в случае шардирования можно заказать несколько машин m4.large вместо того, чтобы переходить на более дорогой m4.2xlarge. Такое распределение данных может быть полезно и в случае большой нагрузки на процессор. Например, если у вас 15 Gb данных, то в случае кластера на m4.large у вас будет 3 машины (по 2vCPU и 6.5Gb стоимостью ~$300), а без него — одна m4.2xlarge (8vCPU и 30Gb стоимостью ~$1200). Ещё одно из преимуществ — автоматическая отказоустойчивость, за количеством и состоянием машин следит AWS. Однако, Redis в режиме кластера статичен — то есть вы не можете добавить шард, либо read-реплику в группу. Выросли объёмы данных? Пересоздавайте кластер. К слову, создание любого ElasiCache объекта — довольно продолжительная операция. Например, кластер из двух шардов по 2 ноды в каждом готовился около 10 минут. Итак, вот список ограничений кластера:
мультизонность с отказоустойчивостью включены по умолчанию и обязательны
вы не можете вручную выбирать мастер
каждый шард должен иметь как минимум одну read-реплику (то есть минимум 2 инстанса)
структура кластера — тип инстансов, их количество, параметры шардирования, — не могут быть изменены иначе, кроме как пересозданием кластера.
Основные настройки
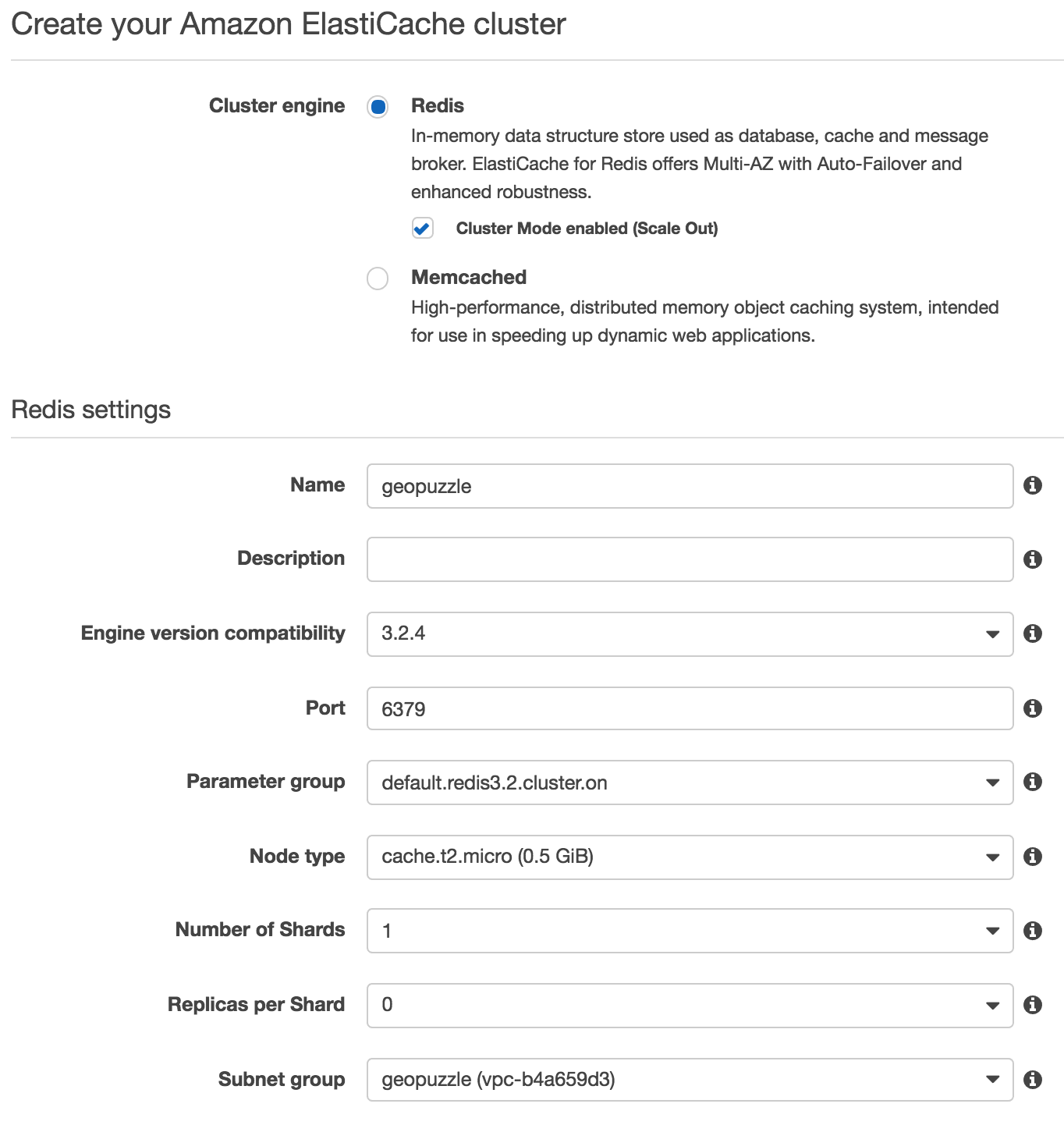
 В первом блоке необходимо определиться с основными параметрами кластера. Parameter Group здесь имеет тот же смысл, что и у RDS — позволяет редактировать конфиг Redis. При выборе типов узлов имейте ввиду одну особенность — t2 инстансы несколько отличаются от всех остальных. Для них недоступны бэкапы (как ручные, так и автоматические) и автоматическая отказоустойчивость.
В первом блоке необходимо определиться с основными параметрами кластера. Parameter Group здесь имеет тот же смысл, что и у RDS — позволяет редактировать конфиг Redis. При выборе типов узлов имейте ввиду одну особенность — t2 инстансы несколько отличаются от всех остальных. Для них недоступны бэкапы (как ручные, так и автоматические) и автоматическая отказоустойчивость.
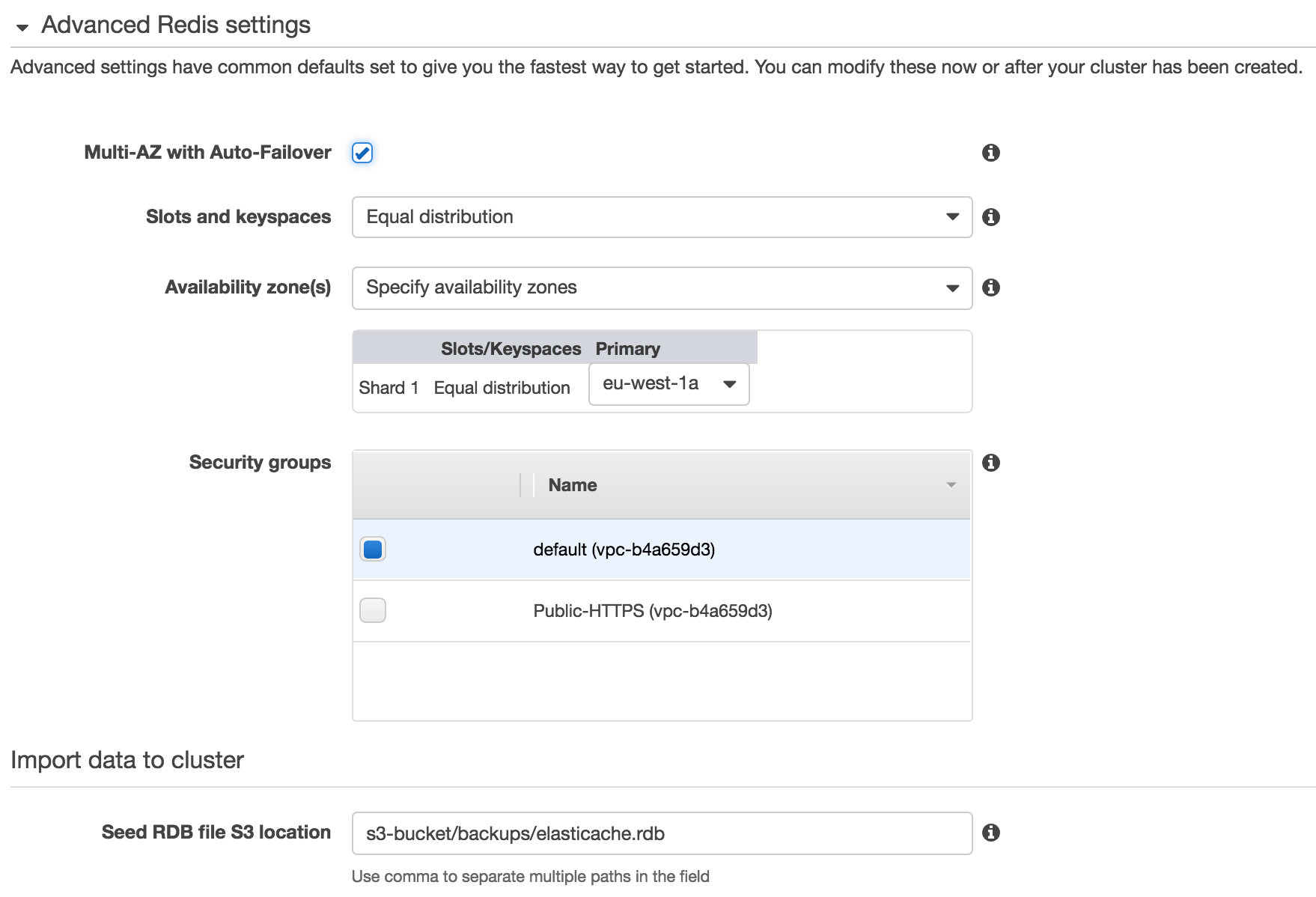
В дополнительных настройках всё несколько интереснее. Во-первых, галочка Multi-AZ with Auto-Failover, которая гарантирует вам замену машин в случае поломки, а также доступность в нескольких зонах. По умолчанию AWS предлагает создать по инстансу в каждой зоне и автоматически распределить их. Однако, вы можете вручную задать нужные зоны доступности с помощью параметра Preferred availability zone(s).
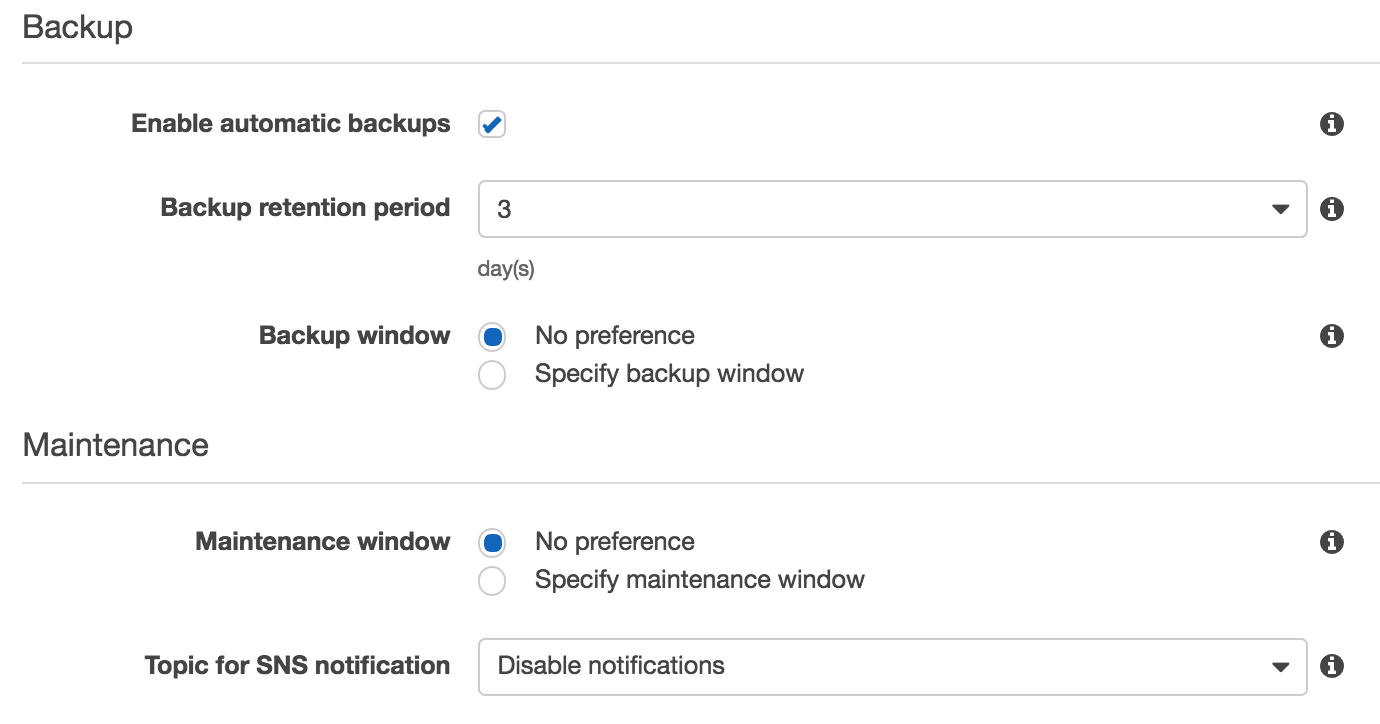
В разделе Import data to cluster можно задать путь к rdb файлу на S3, из которого будут загружаться данные при создании новой машины. Там есть ряд нюансов, описанных ниже в разделе Backup.
В разделе Maintenance указывается временной промежуток для обслуживания инстансов (например, обновления ПО), а также в какой SNS канал отсылать оповещения о подобных событиях.
Работа с кешем
После того, как процесс создания завершится, список будет примерно таким (вверху боевая база, внизу тестовый кластер):
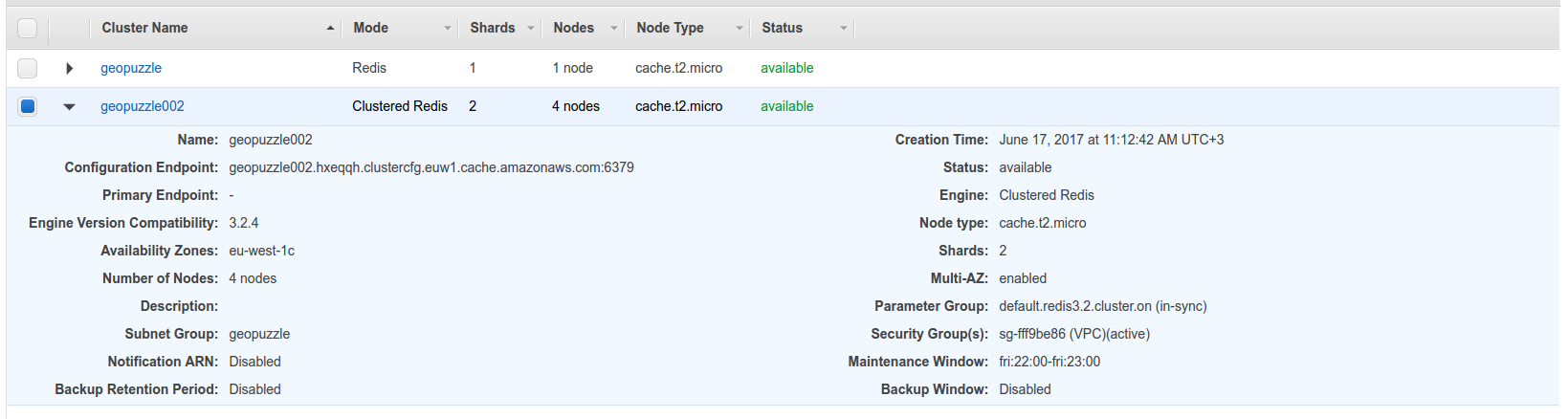 Самый главный вопрос — как подключиться? Для режима кластера доменное имя будет в параметре Configuration Endpoint, для обычного — в Primary Endpoint (какой инстанс на данный момент является мастером). Я намеренно отключил создание бэкапов и нотификацию, чтобы проверить возможность их включения в дальнейшем — работает. Для просмотра содержимого — кликните по имени.
Самый главный вопрос — как подключиться? Для режима кластера доменное имя будет в параметре Configuration Endpoint, для обычного — в Primary Endpoint (какой инстанс на данный момент является мастером). Я намеренно отключил создание бэкапов и нотификацию, чтобы проверить возможность их включения в дальнейшем — работает. Для просмотра содержимого — кликните по имени.
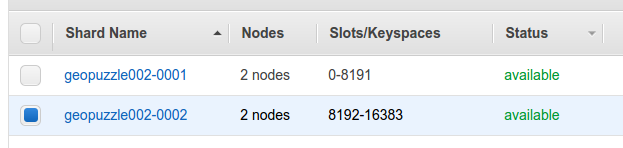 Для кластера будет ещё одна промежуточная страница со списком шардов, через которую можно попасть уже в конкретную группу машин с одним мастером и несколькими репликами. Для каждой из них указан endpoint, что даёт возможность анализа конкретной машины, а также кучу метрик по ней.
Для кластера будет ещё одна промежуточная страница со списком шардов, через которую можно попасть уже в конкретную группу машин с одним мастером и несколькими репликами. Для каждой из них указан endpoint, что даёт возможность анализа конкретной машины, а также кучу метрик по ней.

Метрики ElastiCache
На данный момент существуют следующие метрики, которые также доступны и из CloudWatch.
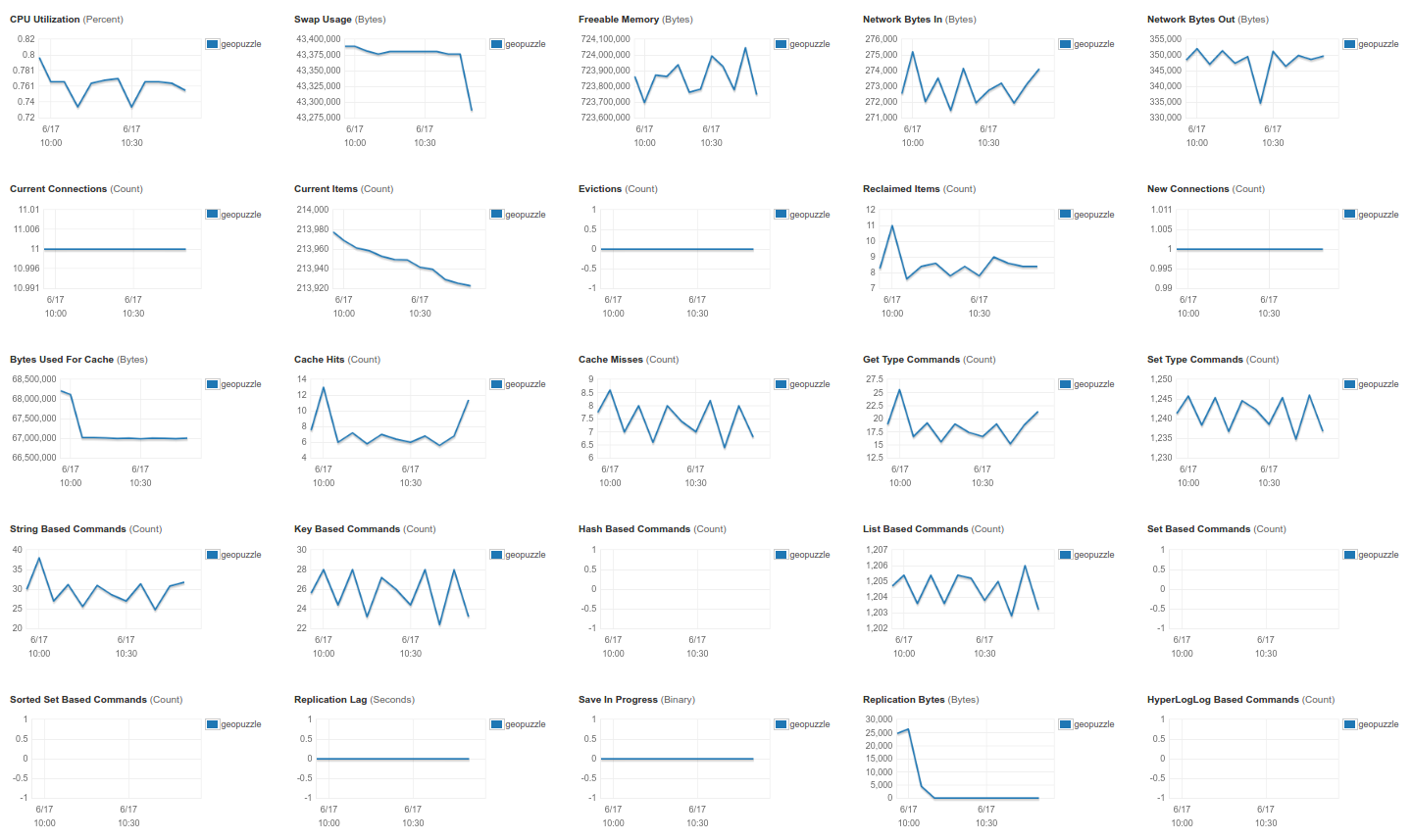 Помимо системных (первый ряд), все остальные специфичны для ElastiCache.
Помимо системных (первый ряд), все остальные специфичны для ElastiCache.
Current Items (кол-во элементов) и Bytes Used For Cache (кол-во занимаемых байт) показывают заполнение базы Evictions и Reclaimed Items — кол-во ключей, которые были вытеснены из базы, и кол-во протухших ключей соответственно Cache Hits и Cache Misses — попадания и промахи, по ним можно оценить насколько эффективно кеширование Get Type Command и Set Type Command — общее количество операций чтения и записи ключей String/Key/Hash/List/Set/Sorted Set Based Command — данные из Redis commandstats Replication Lag, Save In Progress, Replication Bytes, HyperLogLog Based Command — отвечают за успешность репликации (сколько байт передано, с какой задержкой). На графике Replication Bytes можно заметить, что я недавно отключил репликацию
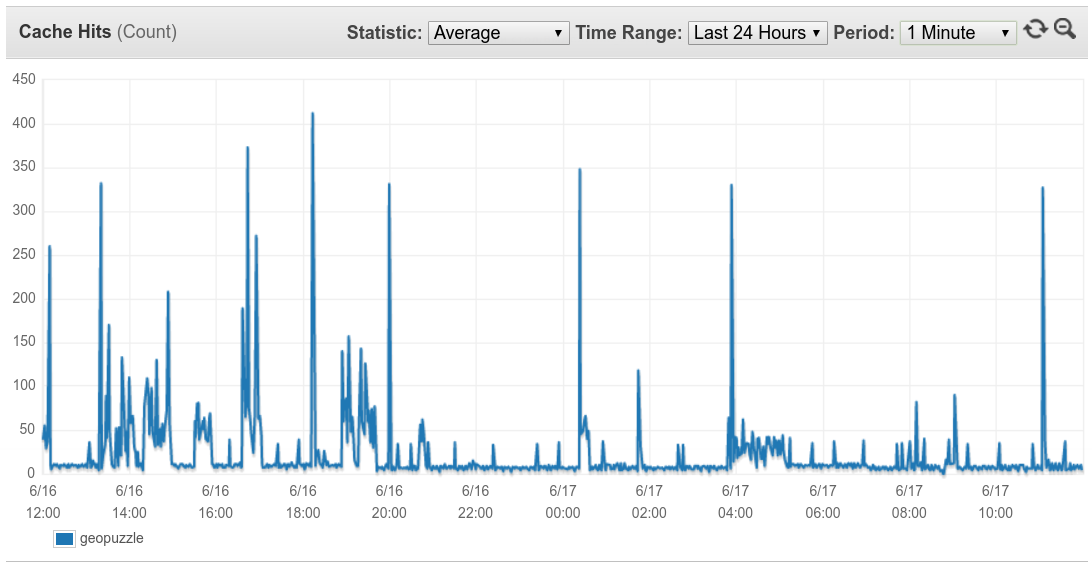 По каждой из них можно настроить нотификацию. Например, у меня установлены на CacheMisses > 100 (пользователи пытаются обратиться к несуществующим элементам) и CurrItems < 200 000 (что-то вымылось из кеша). Также для проекта показателен график Cache Hits — по нему видно когда пользователь начинал игру, и даже можно предположить какую именно (по количеству чтения записей).
По каждой из них можно настроить нотификацию. Например, у меня установлены на CacheMisses > 100 (пользователи пытаются обратиться к несуществующим элементам) и CurrItems < 200 000 (что-то вымылось из кеша). Также для проекта показателен график Cache Hits — по нему видно когда пользователь начинал игру, и даже можно предположить какую именно (по количеству чтения записей).
Backup
Обычно в кеш сбрасывают сессии пользователей, сгенерированный HTML, результаты SQL запросов и прочую информацию, которую не страшно потерять, так как она может быть сгенерирована заново в разумный срок. Я же помимо всего перечисленного храню там предрасчитанные значения полигонов, вычисление каждого из которых может занимать продолжительное время. Так что потеря инстанса с этой информацией может обернуться несколькими часами простоя, что даже для pet-проекта недопустимо. Самое время позаботиться о бэкапе 🙂
AWS предоставляет возможность автоматического создания бэкапов, но только не для инстансов t2 (ошибка SnapshotFeatureNotSupportedFault), которые даются бесплатно в рамках Free Tier. Да, вот такая вот засада, так что пришлось писать небольшой скриптик для дампа содержимого. Мне не удалось получить результат сразу в виде rdb файла, так что я залил дамп сначала в локальный Redis, а уже из него выгрузил записи в формате, пригодном для импорта при создании кластера, с помощью команды SAVE. Посмотреть где находится локальный файл можно в настройках Redis в разделе SNAPSHOTTING. Есть ещё пара нюансов (они также описываются здесь, шаг 4):
чтобы ElasiCache смог получить доступ к вашему rdb файлу на S3, необходимо разрешить пользователю aws-scs-s3-readonly его читать/писать, а также читать разрешения. Права надо выдать именно на конкретный файл, идентификатор пользователя 540804c33a284a299d2547575ce1010f2312ef3da9b3a053c8bc45bf233e4353;
в rdb файле должна быть только одна — нулевая! — база данных.
Заключение
Пункты меню Reserved Nodes, Parameter Groups, Subnet Groups и Events имеют тот же смысл, что и других сервисов, и подробно описаны здесь. На этом обзор ElastiCache можно считать оконченным, и для быстрого старта его должно хватить. Если я что-то упустил — пишите в комментариях.